快速结论
ClipCombo 最初要解决的是一个很朴素的问题:直播、播客、访谈、课程和长录屏里有太多内容,创作者需要快速找到值得发布的片段,去掉停顿,补上字幕,然后导出成短视频。
这个方向仍然是 ClipCombo 的根。我们不会把简单的切片工作流做复杂。Clip mode 仍然应该小而美:导入一个长视频,识别字幕,检测停顿,找出高光,生成多个可用片段。
但我们也发现,只做切片不够。创作者拿到一个好片段之后,很快会想加一个表情包、一个数据卡片、一个标题动画、一个 B-roll、一个分屏画面,或者把多个视频源组合在一起。如果这时直接跳到 After Effects 级别的复杂度,很多人会被时间线、属性树、预合成、关键帧和渲染设置劝退。
所以 ClipCombo 的下一步不是把 clip mode 变成臃肿的专业软件,而是引入一个清楚的分层:简单切片继续简单,需要进阶时再创建 composition。composition 承载多轨道、预合成、HTML/MG 图层、关键帧和 Agent 生成的动画。AI 的角色不是替代创意,而是把那些耗时但可描述的剪辑与动效任务加速掉。
初心:先把重文本长视频切快
长视频切片有一个天然适合 AI 的入口:文本。
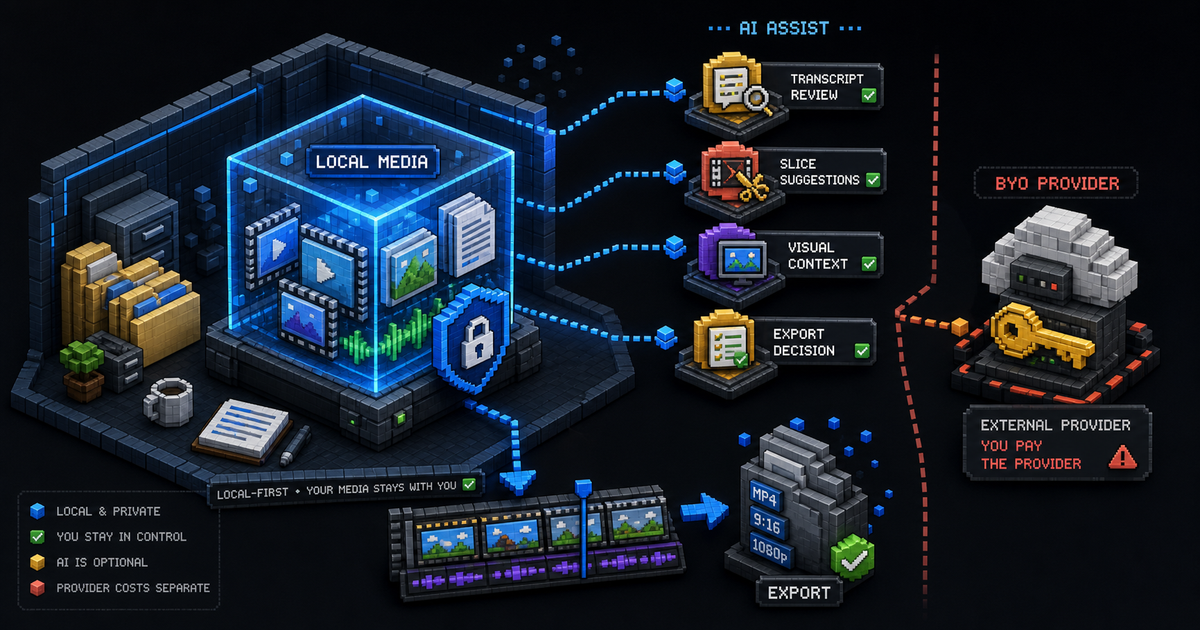
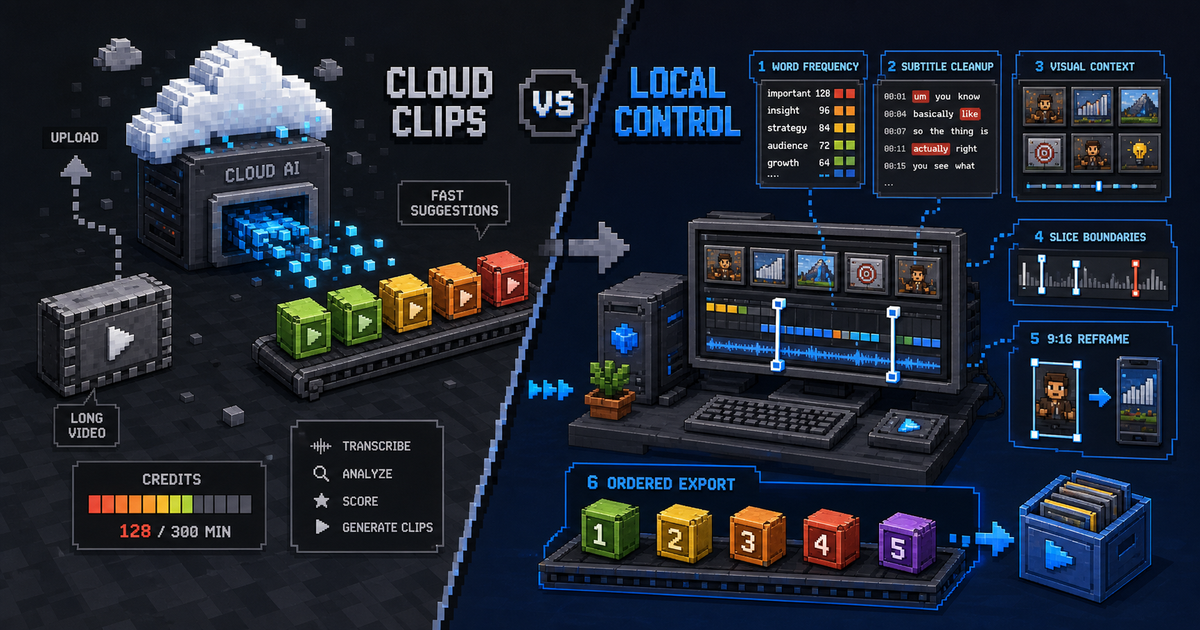
直播、podcast、访谈、讲座和会议录屏通常是重文本内容。ASR 把语音转成字幕后,LLM 就能理解话题、转折、情绪、笑点、观点密度和可传播的句子。再配合 VAD 去除停顿、字幕分段、词频复查和高光片段建议,用户不必从一小时素材里一点点拖播放头。
这就是 ClipCombo 的第一阶段产品直觉:
| 痛点 | ClipCombo 的第一层能力 |
|---|---|
| 不知道长视频哪里值得剪 | ASR transcript、LLM 高光建议、可回到时间线的片段定位 |
| 剪掉停顿很烦 | VAD 自动切片与一键去停顿 |
| 字幕耗时 | ASR 上字幕、字幕拆分、词频复查 |
| 竖屏发布要重复调整 | 9:16 构图与批量导出 |
| 长素材太多 | 多 clip 组织、批量导出、后续视觉关键帧索引 |
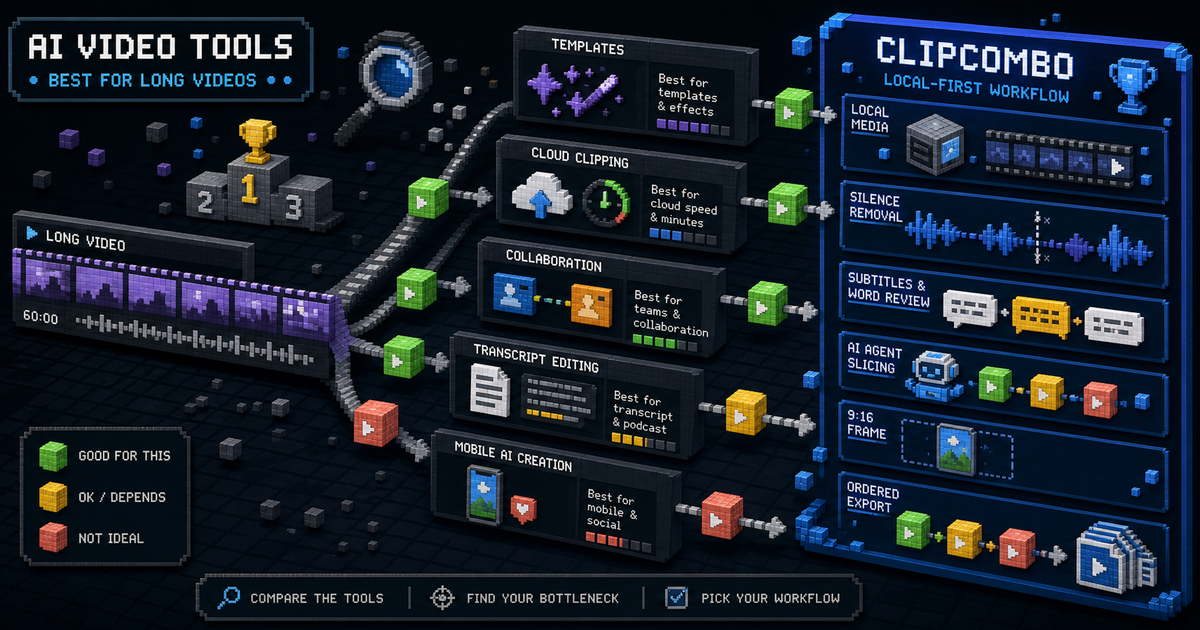
CapCut 的 auto captions、filler word removal 和易上手时间线证明了一点:大量创作者并不想每天都打开复杂后期工程,他们想要“把一条 15 分钟视频很快变成能发布的几个短视频”。OpusClip 也验证了另一个方向:云端 AI 可以从长视频里自动找候选 clip,并用多模态线索理解画面、声音和情绪。
ClipCombo 从这些产品里学到的是:第一步必须快。切片、去停顿、上字幕、找 highlight,不能让用户先学习一套专业后期系统。
为什么只做切片会碰到天花板
问题出现在“片段已经找到了”之后。
一个 45 秒的 podcast 精华片段,如果只是加字幕,它很快能发布。但如果用户想进一步表达观点,往往需要额外的视觉语言:
| 想表达的内容 | 需要的编辑能力 |
|---|---|
| 这句话很关键 | 文字强调、缩放、描边、弹入动画 |
| 这里有一个梗 | 表情包、图片图层、音效、短暂叠加 |
| 这里在讲数据 | 数据卡片、数字滚动、图表动画 |
| 这里要对比两个人 | 分屏、多视频源、裁切和同步 |
| 这里要解释流程 | 箭头、框选、UI callout、MG 动画 |
传统软件会把这些能力放在复杂的时间线和属性系统里。After Effects 的预合成、嵌套 composition 和关键帧插值非常强大,但代价也很明显:一秒钟精致动画,现实中可能要花一小时甚至更久。
剪映和 CapCut 代表的是另一种比例:很多创作者可以花 10 分钟处理一个 15 分钟视频,因为模板、字幕、基础特效和移动端工作流把大多数步骤压扁了。
ClipCombo 想填的是这两个世界中间的空隙:
- 不让普通创作者一上来面对 After Effects 的完整复杂度。
- 不把高质量 MG 动画降级成几个固定模板。
- 让 AI 负责生成、调整和解释复杂动画层,人类负责判断创意和节奏。
- 让生成出来的结果仍然是可编辑 layer,而不是一个黑盒视频片段。
市场给出的两个重要信号
过去几年有两个信号改变了我们对视频编辑器的判断。
第一个信号来自 Remotion。Remotion 用 React 描述视频 composition,并通过 width、height、fps、durationInFrames、inputProps 等配置进行程序化渲染。它证明了一件事:视频不一定只能在传统 NLE 的 UI 里被创作,也可以被代码、数据和组件生成。
Remotion 的启发不是“ClipCombo 应该直接迁移成 Remotion”。原因很现实:Remotion 更适合可信开发者工程和程序化视频模板,它的 client-side web renderer 官方仍标记为 experimental,而且商业集成还需要认真看 license。ClipCombo 的 composition document、素材库、时间线、操作历史和本地优先数据模型必须继续由自己掌握。
第二个信号来自 HyperFrames。HyperFrames 把 HTML 作为视频 authoring surface,用 seek clock 逐帧推进时间,再捕获每一帧像素。它特别适合 Agent:LLM 很擅长写 HTML/CSS/JS,如果能把这些网页式动画变成逐帧可复现的视频,MG 创作门槛会明显降低。
HyperFrames 给 ClipCombo 的启发更直接:HTML/MG 不应该只是“导出前烘焙成视频”的旁路能力,而应该成为一个 first-class layer。用户或 Agent 可以生成 lower third、标题卡、数据卡片、UI callout、CSS/GSAP 动画;ClipCombo 则负责 sandbox、依赖 allowlist、逐帧 seek、浏览器捕获、最终合成和导出。
竞品和框架的取舍
下面这张表不是说谁更好,而是说明 ClipCombo 从不同产品和框架里学到了什么,以及我们不会照搬什么。
| 产品或框架 | 公开口径里的强项 | ClipCombo 学到的东西 | ClipCombo 的取舍 |
|---|---|---|---|
| CapCut / 剪映 | auto captions、去 filler words、模板化剪辑、低学习成本 | 粗剪和字幕必须极快,普通用户不应该先理解复杂工程 | 保持 clip mode 小而美,不把所有高级面板塞进第一屏 |
| OpusClip | 从长视频自动生成短片,使用视觉、音频、情绪等多模态线索 | AI clipping 的用户价值成立,VLM 可以补齐“画面发生了什么” | 不把选择权完全交给云端黑盒,保留本地优先和人工复查 |
| After Effects | 预合成、嵌套 composition、keyframe、layer/property 心智 | 复杂后期应该拆成 composition、layer、property、keyframe | 渐进暴露 AE-like 能力,避免把初学者直接推入完整复杂度 |
| Remotion | React 组件化视频、数据驱动渲染、服务端或本地程序化输出 | frame-driven thinking 很适合可重复视频生成 | 不把 Remotion 作为 canonical renderer,避免双重工程世界和 license 风险 |
| HyperFrames | HTML-first、agent-first、seek clock、逐帧浏览器捕获 | HTML 是 LLM 生成 MG 的高杠杆 authoring layer | 采用 HTML browser capture 的架构方向,但 ClipCombo 继续拥有 composition 数据和最终合成 |
ClipCombo 的结论是:第三方框架可以启发 renderer adapter、动画 runtime 或模板系统,但不能拥有最终的 composition truth。
ClipCombo 的产品理念:clip 简单,composition 进阶
产品层面,我们把 ClipCombo 拆成两个互相连通但心智不同的空间。
Clip mode 负责“从长素材里找出能用的片段”。它围绕单一 source 工作,主要能力是 ASR、VAD、字幕、视觉关键帧、词频复查、LLM 切片建议、构图和导出。
Composition mode 负责“把片段变成完整作品”。它允许多个素材源、多层图层、嵌套 composition、text layer、shape layer、HTML/MG layer、transform、opacity、blend mode、keyframe 和未来的 effect stack。
最重要的是,用户不需要一开始就进入 composition。当一个 clip 已经够好,用户应该可以直接导出。当用户想继续加动画、叠素材、做分屏、做包装,再创建 composition。这个动作应该像“打开进阶模式”,而不是换一个完全陌生的软件。
预合成是这里的关键抽象。After Effects 里,precompose 可以把多层内容收进新的 composition,再作为父 composition 的一个 layer 使用。ClipCombo 采用类似心智:用户可以把复杂片段打包成一个 composition layer,外层只处理整体 timing、position、scale、rotation、opacity,内层继续保留可编辑细节。
这让复杂度可以被折叠,也让 AI 更容易工作。Agent 可以生成一个 title animation composition,用户只需要把它放到对应时间和位置。如果需要微调,再进入预合成内部修改文案、颜色、节奏或关键帧。
技术核心:一帧只有一个真相
多轨和 MG 最大的坑不是“怎么显示出来”,而是“preview 和 export 是否一致”。
浏览器 DOM 很适合实时交互。拖动图层、播放视频、scrub 时间线、缩放画布,DOM/native media 都很快。但视频导出需要确定性:第 123 帧应该是什么,不能依赖 wall-clock、requestAnimationFrame 或某个 CSS transition 当前刚好跑到哪里。
所以 ClipCombo 的架构原则是:
| 层级 | 职责 |
|---|---|
| Canonical composition document | 保存 layer、timing、z-order、source mapping、property、keyframe、mask、effect、HTML/MG metadata |
| Property / keyframe evaluator | 在指定 composition time 计算 transform、opacity、audio gain、HTML props 等属性 |
| Composition render plan | 把当前帧需要显示的 layer stack 解析成统一渲染计划 |
| Realtime DOM preview | 服务交互速度,是 proxy backend,不是所有功能的像素真相 |
| Exact-frame preview | 用和导出同类的 renderer 检查关键帧像素 |
| Deterministic export | Canvas 2D / WebCodecs baseline,逐帧求值、合成、编码 |
这也是 TODO 里反复强调的 single-source-of-truth。ClipCombo 可以有多个 renderer adapter,但不能有多个语义真相。无论是人类拖拽、快捷键、Inspector 输入,还是 Agent toolcall,都应该通过同一套 composition operation 和 history layer 写入数据。
HTML/MG 为什么值得成为一等图层
我自己每天重度使用 Codex 和 Claude Code,也有 5 年以上 After Effects 与 Adobe 全家桶经验。这个组合让我越来越确定一件事:LLM 现在最擅长生成的复杂视觉载体,不是传统 NLE 的私有模板格式,而是 HTML/CSS/JS。
写一个标题卡、一个 quote card、一个动态数据面板、一个 UI callout,HTML 层非常自然。加上 GSAP 这样的 timeline/easing runtime,Agent 可以把“这里做一个数字上涨动画,最后弹出重点词”变成可运行的代码。
但这也带来风险。ClipCombo 的 HTML/MG 不能变成任意网页:
- 不能 runtime
npm install。 - 不能加载 CDN script。
- 不能访问网络、cookies、secrets 或宿主 DOM。
- 不能让未知 import 悄悄进入导出流程。
- 不能用 wall-clock ticker 驱动最终导出。
因此我们的策略是:HTML/MG layer 运行在 sandbox 中,依赖来自已审核、已 pin、app-bundled 的 allowlist。GSAP core 会作为第一批 runtime,但 timeline 必须被 ClipCombo 的 frame time 驱动,比如暂停后按 timeSeconds seek,而不是自由播放。
更进一步,HTML/MG 的外层 transform 也不属于生成代码。生成代码只负责 layer local surface 内的内容。position、scale、rotation、opacity、blend mode、timing、z-order 仍然由 ClipCombo 的通用 layer system 控制。这样 canvas 选中、timeline 修剪、预合成、导出、undo/redo 和 Agent diff 都能对齐。
AI 在中间层的真正价值
AI 不是把剪辑变成一句 prompt 就结束。真正有价值的地方,是它可以在不同复杂度的阶段加速不同类型的劳动。
| 阶段 | 人类最烦的事 | AI 应该做的事 |
|---|---|---|
| 粗剪 | 从长视频里找亮点 | 读 ASR、VLM、关键词和画面描述,提出 clip 候选 |
| 清理 | 去停顿、补字幕、修重复错误 | 应用 VAD、字幕分段、词频复查、ASR 修正建议 |
| 精剪 | 调整节奏、组织素材 | 根据用户意图移动 layer、拆分片段、建立 composition |
| 动效 | 做 MG、关键帧、标题动画 | 生成 HTML/MG layer、shape/text animation、可编辑 props |
| 导出 | 等待、失败、重跑 | 提供确定性 export、进度、重试、恢复和诊断 |
这也是 ClipCombo 不想只做“AI 自动出片”的原因。自动出片很有用,但它不是全部。很多时候,用户真正想要的是:我知道这段话要表达什么,你帮我把那段复杂但耗时的动效做出来;我再判断它是否有品味,是否符合节奏,是否真的表达了我的想法。
这更接近“pre-Adobe”的体验:仍然保留剪辑与后期的精度,但复杂操作由 Agent 帮你进入和退出。
下一步最难的不是功能,而是信任
多轨、HTML/MG、Agent 编辑都很兴奋,但 ClipCombo 现在最谨慎的地方是 preview/export parity。
如果用户在 preview 里看到的字幕换行、HTML 动画、mask、blend mode、nested composition 和导出结果不一致,产品信任会立刻下降。越是 AI 生成的内容,越需要可审查和可复现。
所以短期优先级不是堆更多炫酷 layer,而是把几件事做稳:
- exact-frame preview 成为 parity-sensitive feature 的 review surface。
- deterministic export 继续使用共享 render graph 和固定 frame timestamp。
- HTML/MG 在没有 browser capture runtime 时明确显示 fallback 或 unsupported export state。
- Agent 生成的内容保持可检查、可撤销、可编辑。
- clip mode 不被多轨复杂度污染。
ClipCombo 会继续从一个很实际的起点出发:先让长视频切片省时省力,再在用户需要更高表达力时,打开 composition。我们希望最终的体验不是“AI 替你做完一个你无法理解的视频”,而是“AI 把耗时的技术劳动折叠起来,让你重新把注意力放回创意剪辑本身”。