
要点
ClipCombo の出発点はとてもシンプルです。長尺動画には素材が多すぎるので、クリエイターは使える瞬間をすばやく見つけ、無音や間を整理し、字幕を付け、短いクリップとして書き出したい。
この方向性は変わりません。Clip mode はこれからも小さく、速く、使いやすい状態を守ります。1 本のソース動画を読み込み、文字起こしし、無音を検出し、ハイライトを見つけ、字幕を確認し、公開できるクリップを書き出す場所です。
ただし、切り出しだけでは限界があります。良いクリップが見つかったあと、ユーザーはミーム画像、タイトルアニメーション、データカード、B-roll、分割画面、説明用のモーショングラフィックスを足したくなります。その瞬間に After Effects の複雑さへ一気に飛ぶのは、多くの編集者にとって重すぎます。
そこで ClipCombo は clip mode を重くするのではなく、composition mode を追加します。clip mode は速い切り出しを担当し、composition mode はマルチトラック編集、プリコンポーズ、HTML/MG レイヤー、キーフレーム、Agent が生成するモーショングラフィックスを担当します。
最初の仕事: テキスト中心の長尺動画を速く切る
ライブ配信、ポッドキャスト、インタビュー、講義、ウェビナー、画面収録は、AI クリッピングと相性が良い素材です。音声を ASR でテキスト化すると、LLM は話題、転換点、冗談、主張、感情、密度の高い箇所を理解できます。
ClipCombo の第一層はここにあります。
| 編集の負担 | ClipCombo の第一層 |
|---|---|
| 使える箇所を探す | transcript 検索、LLM のハイライト提案、時間位置への復帰 |
| 無音や間を消す | VAD による無音削除 |
| 字幕を付ける | ASR 字幕、字幕分割、単語頻度レビュー |
| 縦型動画を作る | 9:16 フレーミングと書き出し |
| 候補が多い | 複数 clip の整理とバッチ書き出し |
CapCut は、速い字幕、filler word removal、学習コストの低いタイムラインがどれほど重要かを示しています。OpusClip は、長尺動画から AI が短尺候補を提案するカテゴリそのものを検証しました。視覚、音声、感情の手がかりを使えることも重要です。
ClipCombo はそこから学びつつ、別の境界を置きます。最初のステップは速く、可能な限り local-first で、ユーザーが確認しやすいものであるべきです。
切り出しだけでは足りない理由
限界は、クリップが見つかったあとに現れます。
45 秒のポッドキャスト切り抜きは字幕だけでも公開できます。しかし、アイデアをより強く伝えたい場合、追加の視覚表現が必要になります。
| 表現したいこと | 必要な編集能力 |
|---|---|
| 重要な一文を強調する | 文字アニメーション、拡大、アウトライン、出現タイミング |
| 冗談を足す | ミーム画像、短いオーバーレイ、効果音 |
| 数字を説明する | データカード、カウントアップ、チャートアニメーション |
| 2 人を比較する | 分割画面、複数ソース、クロップと同期 |
| UI 操作を説明する | 矢印、コールアウト、画面ハイライト、MG アニメーション |
After Effects は、レイヤー、プリコンポーズ、ネスト、キーフレーム、補間によって非常に強力です。一方で、精密な 1 秒を作るために現実の 1 時間が必要になることもあります。
CapCut などは別の編集比率を作っています。よくある作業がテンプレートと簡単な操作に圧縮されるので、ユーザーは 10 分で 15 分の動画を実用的に整えられます。
ClipCombo が狙うのは、この 2 つの世界の間です。
- 一般のクリエイターをいきなり After Effects の複雑さへ押し込まない。
- 表現力を固定テンプレートだけに閉じ込めない。
- 複雑なアニメーション層は AI が生成、調整できるようにする。
- 生成結果は不透明な動画ではなく、編集可能なレイヤーとして残す。
市場から見えた 2 つのシグナル
1 つ目は Remotion です。Remotion は React component で動画を記述し、width、height、fps、durationInFrames、inputProps などの composition config からレンダリングします。動画は従来の NLE UI だけでなく、コード、データ、再利用可能な component からも作れることを示しました。
ただし、ClipCombo が Remotion ラッパーになるという意味ではありません。Remotion は信頼された開発者プロジェクトやプログラマブルなテンプレートに強い一方、client-side web renderer は公式に experimental とされ、商用利用では license も確認が必要です。ClipCombo は composition document、素材ライブラリ、タイムライン、操作履歴、local-first workflow を自分で持つ必要があります。
2 つ目は HyperFrames です。HyperFrames は HTML を動画の authoring surface として扱い、seek clock で時間を進め、フレームごとに pixel を capture します。これは Agent と相性が良い考え方です。LLM は HTML、CSS、JavaScript を書くのが得意だからです。
ClipCombo にとっての学びは明確です。HTML/MG は一級レイヤーにする価値があります。ユーザーや Agent は lower third、title card、quote card、data card、UI callout、GSAP animation を生成できます。ClipCombo は sandbox、dependency allowlist、frame seek、exact-frame capture、親 composition への合成、書き出しを担当します。
それぞれから学ぶこと
| ツール / フレームワーク | 公開されている強み | ClipCombo が学ぶこと | ClipCombo の選択 |
|---|---|---|---|
| CapCut | 字幕、filler word removal、テンプレート、低い学習コスト | 粗編集と字幕は速くなければならない | clip mode を軽く保つ |
| OpusClip | 長尺動画から AI が短尺候補を生成し、マルチモーダルな手がかりを使う | AI clipping には価値があり、視覚文脈も重要 | すべてをブラックボックスに任せず local-first な確認を残す |
| After Effects | プリコンポーズ、ネスト、キーフレーム、レイヤー / プロパティモデル | 複雑な動画編集には構成可能な layer が必要 | AE-like な力を段階的に出す |
| Remotion | React video、データ駆動レンダリング、プログラム出力 | frame-driven generation は強いモデル | canonical renderer にはしない |
| HyperFrames | HTML-first、agent-first、seek-driven capture | HTML は MG authoring layer として高いレバレッジがある | browser capture の方向を採用しつつ、composition graph は ClipCombo が持つ |
外部フレームワークは adapter、runtime、template の参考になりますが、ClipCombo の visual truth は所有しません。
Product Model: clip は簡単に、composition は高度に
ClipCombo には、つながっているが役割の違う 2 つの編集空間があります。
Clip mode は「このソースのどこを使うべきか」に答えます。1 本のソース動画を中心に、transcript、無音範囲、visual keyframes、単語頻度レビュー、ハイライト提案、framing、clip export を扱います。
Composition mode は「clip と素材をどう完成動画にするか」に答えます。複数素材、layer、nested composition、text layer、shape layer、HTML/MG layer、transform、opacity、blend mode、keyframes、将来の effect stack を扱います。
ユーザーは最初から composition mode を使う必要はありません。clip がそのまま使えるなら書き出せばよい。タイトルアニメーション、複数トラック、分割画面、生成された説明アニメーションが必要になったら composition を作ります。
ここで重要なのがプリコンポーズです。After Effects では、選択した layer を新しい composition に入れ、それを親 composition の 1 layer として扱えます。ClipCombo も同じメンタルモデルを採用します。複雑さは 1 つの layer に折りたたみ、必要なら内部を開いて編集できます。
これは AI にも向いています。Agent が title animation composition を生成し、ユーザーは時間と位置を合わせる。調整したければ precomp の中に入り、文言、色、タイミング、keyframe を直します。
技術の中心: 1 フレームに 1 つの真実
マルチトラック編集と MG で難しいのは、何かを表示することではありません。preview と export を一致させることです。
ブラウザ DOM は realtime interaction に向いています。layer を動かす、scrub する、動画を再生する、canvas を zoom する、といった操作は DOM と native media が得意です。しかし export は決定的でなければなりません。123 フレーム目は composition data と time の関数であるべきで、wall-clock animation の副作用で決まってはいけません。
ClipCombo は 1 つの semantic pipeline を中心にします。
| 層 | 役割 |
|---|---|
| Canonical composition document | layer、timing、z-order、source mapping、properties、keyframes、masks、effects、HTML/MG metadata を保存 |
| Property / keyframe evaluator | 指定時刻の transform、opacity、audio gain、HTML props などを計算 |
| Composition render plan | 現在フレームの active layer stack を解決 |
| Realtime DOM preview | 操作速度のための proxy backend |
| Exact-frame preview | parity-sensitive な確認を export と同種 renderer で行う |
| Deterministic export | 固定 timestamp でフレームを評価、合成、Canvas/WebCodecs baseline で encode |
このため ClipCombo は dual-pipeline trap を避けます。CSS や DOM preview が見た目の真実になり、export が Canvas や WebCodecs で別実装になると、いずれ差分が出ます。人間の drag、shortcut、inspector の入力、Agent toolcall は、すべて同じ composition operation と history layer を通して data を変更する必要があります。
HTML/MG を一級レイヤーにする理由
Codex や Claude Code を毎日重く使い、After Effects と Adobe workflow も長く使ってきた経験から、今の LLM にとって自然な複雑ビジュアル形式は、NLE の私有テンプレート形式ではなく HTML、CSS、JavaScript だと感じています。
title card、quote card、data panel、UI callout は HTML と相性が良い。GSAP のような runtime を使えば、「数字をカウントアップして、最後にキーワードをポップさせる」という指示を runnable motion にできます。
ただし ClipCombo の HTML/MG は任意の web page ではありません。生成レイヤーが runtime package install、CDN script、network access、cookie、secret、host DOM access、free-running ticker を使うことはできません。
方向性は次の通りです。
- HTML/MG は sandbox で実行する。
- dependency は review 済み、pin 済み、app-bundled の allowlist から使う。
- GSAP core を最初の runtime として採用するが、timeline は ClipCombo の frame time で seek する。
- layer-level transform は生成コードの外側に置く。
- 生成結果は layer data、props、bindings、keyframes として編集可能に残す。
つまり、生成 HTML は layer local surface の中身を担当します。timing、z-order、transform、opacity、blend mode、undo、review、export は ClipCombo が担当します。
AI の本当の役割
AI は編集全体を 1 prompt と謎の結果に潰すものではありません。各段階の違う種類の作業を加速するものです。
| 段階 | 人間がつらいこと | AI の役割 |
|---|---|---|
| 粗編集 | 長尺素材から強い瞬間を探す | ASR、VLM description、visual keyframes、keywords を読む |
| 整理 | 無音削除と字幕修正 | VAD、字幕分割、ASR 修正案 |
| 精編集 | timing と素材を整理する | layer 移動、clip 分割、review 可能な operation で composition を組む |
| Motion | MG と keyframes を作る | HTML/MG layer、text/shape animation、editable props を生成 |
| Export | 待ち時間、失敗、再実行 | deterministic export、progress、retry、recovery、diagnostics |
これは「pre-Adobe」的な編集体験に近いものです。精密な編集能力は残しながら、退屈で技術的な作業を Agent が折りたたむ。ただし結果は常に確認でき、編集できる状態にします。
次に難しいのは機能ではなく信頼
マルチトラック、HTML/MG、Agent editing は魅力的です。しかし今いちばん慎重に扱うべきなのは preview/export parity です。
preview で見た字幕の折り返し、blend mode、mask、nested composition、HTML animation が export で変われば、信頼は壊れます。AI 生成のビジュアルには、むしろより強い確認可能性が必要です。
そのため短期優先度は、派手な layer type を増やすことではありません。
- Exact-frame preview を parity-sensitive feature の review surface にする。
- Deterministic export は shared render graph と固定 frame timestamp を使い続ける。
- Browser capture がない HTML/MG は fallback または unsupported export state を明示する。
- Agent 生成コンテンツは inspectable、undoable、editable に保つ。
- Clip mode を composition の複雑さから守る。
ClipCombo の方向性は、速い切り出しを速いまま保ち、必要になった時だけ composition を開くことです。AI がユーザーに理解できない動画を勝手に作るのではなく、時間のかかる技術作業を折りたたみ、クリエイターが編集そのものに集中できるようにすることを目指しています。
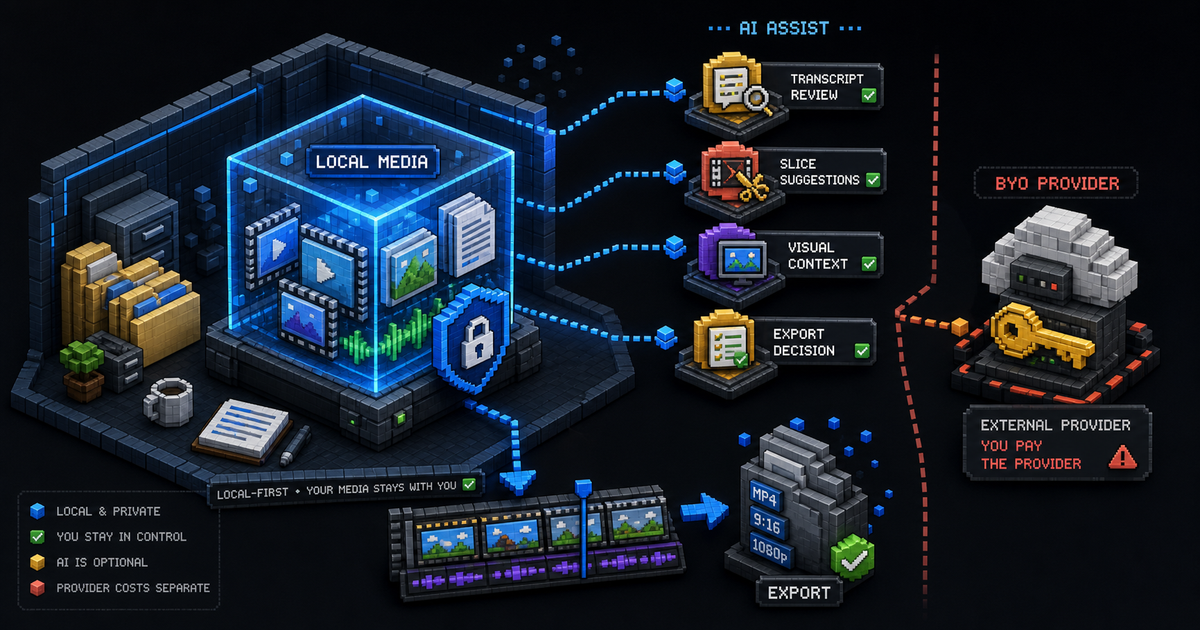
ClipComboにおけるローカル優先AI動画エディタとは
ClipComboはメディア作業をローカル優先に保ちつつ、字幕確認、切り出し、視覚文脈、書き出し判断にAIを任意の助手として使います。
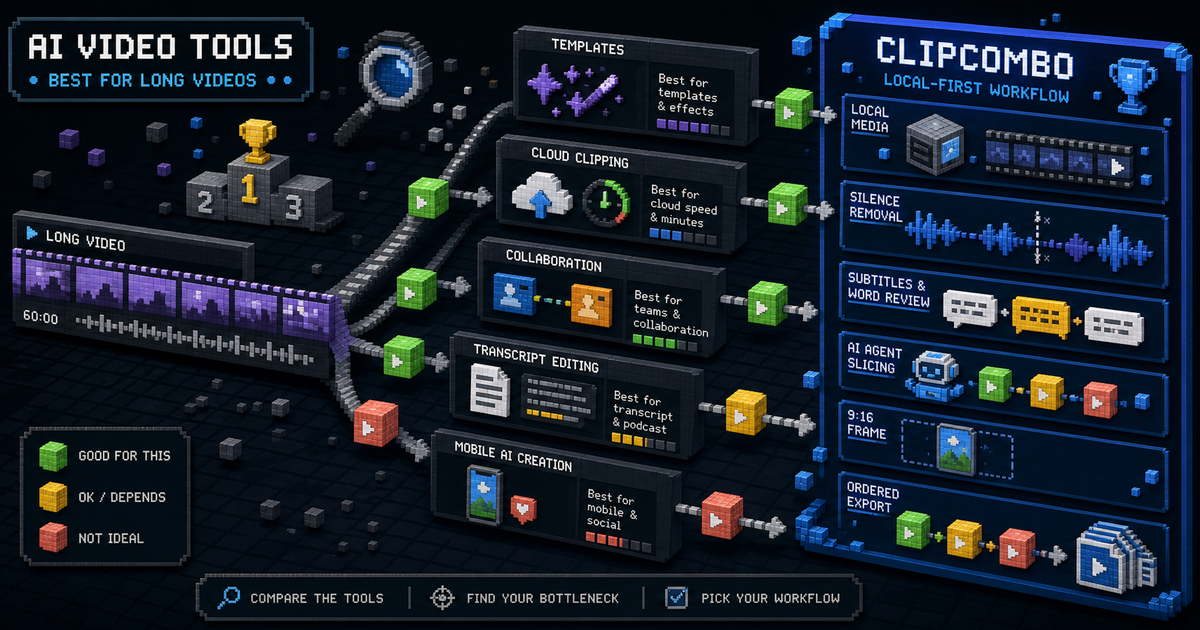
長尺動画向けAI動画クリップツール比較
CapCut、OpusClip、Vizard、Kapwing、Captions、Descript、ClipComboを、長尺動画からショートクリップを作る用途で比較します。
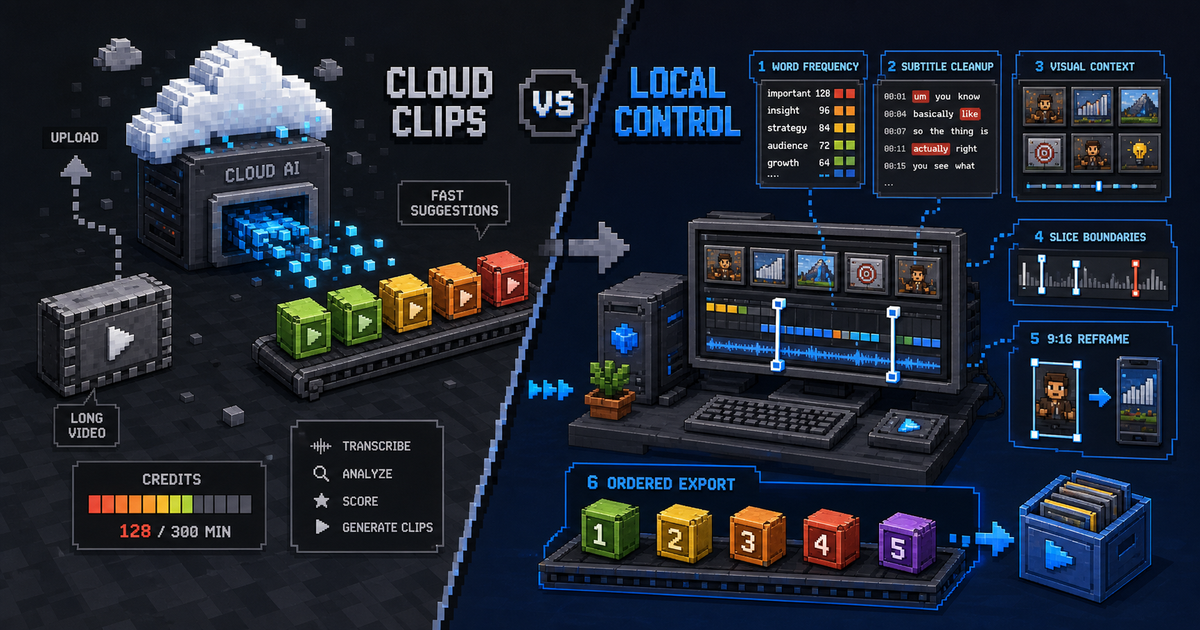
OpusClip代替:ローカル優先のクリップ作業が合う場面
OpusClipとClipComboを、長尺動画クリップ、credits、字幕、Agent支援の切り出し、BYOK型ワークフローで比較します。